Conceptual guide
In this section, you'll find explanations of the key concepts, providing a deeper understanding of core principles.
The conceptual guide will not cover step-by-step instructions or specific implementation details — those are found in the How-To Guides and Tutorials sections. For detailed reference material, please visit the API Reference.
Architecture
LangChain as a framework consists of a number of packages.
langchain-core
This package contains base abstractions of different components and ways to compose them together. The interfaces for core components like LLMs, vector stores, retrievers and more are defined here. No third party integrations are defined here. The dependencies are kept purposefully very lightweight.
langchain
The main langchain package contains chains, agents, and retrieval strategies that make up an application's cognitive architecture.
These are NOT third party integrations.
All chains, agents, and retrieval strategies here are NOT specific to any one integration, but rather generic across all integrations.
langchain-community
This package contains third party integrations that are maintained by the LangChain community. Key partner packages are separated out (see below). This contains all integrations for various components (LLMs, vector stores, retrievers). All dependencies in this package are optional to keep the package as lightweight as possible.
Partner packages
While the long tail of integrations is in langchain-community, we split popular integrations into their own packages (e.g. langchain-openai, langchain-anthropic, etc).
This was done in order to improve support for these important integrations.
langgraph
langgraph is an extension of langchain aimed at
building robust and stateful multi-actor applications with LLMs by modeling steps as edges and nodes in a graph.
LangGraph exposes high level interfaces for creating common types of agents, as well as a low-level API for composing custom flows.
langserve
A package to deploy LangChain chains as REST APIs. Makes it easy to get a production ready API up and running.
LangSmith
A developer platform that lets you debug, test, evaluate, and monitor LLM applications.


LangChain Expression Language (LCEL)
LangChain Expression Language, or LCEL, is a declarative way to chain LangChain components.
LCEL was designed from day 1 to support putting prototypes in production, with no code changes, from the simplest “prompt + LLM” chain to the most complex chains (we’ve seen folks successfully run LCEL chains with 100s of steps in production). To highlight a few of the reasons you might want to use LCEL:
-
First-class streaming support: When you build your chains with LCEL you get the best possible time-to-first-token (time elapsed until the first chunk of output comes out). For some chains this means eg. we stream tokens straight from an LLM to a streaming output parser, and you get back parsed, incremental chunks of output at the same rate as the LLM provider outputs the raw tokens.
-
Async support: Any chain built with LCEL can be called both with the synchronous API (eg. in your Jupyter notebook while prototyping) as well as with the asynchronous API (eg. in a LangServe server). This enables using the same code for prototypes and in production, with great performance, and the ability to handle many concurrent requests in the same server.
-
Optimized parallel execution: Whenever your LCEL chains have steps that can be executed in parallel (eg if you fetch documents from multiple retrievers) we automatically do it, both in the sync and the async interfaces, for the smallest possible latency.
-
Retries and fallbacks: Configure retries and fallbacks for any part of your LCEL chain. This is a great way to make your chains more reliable at scale. We’re currently working on adding streaming support for retries/fallbacks, so you can get the added reliability without any latency cost.
-
Access intermediate results: For more complex chains it’s often very useful to access the results of intermediate steps even before the final output is produced. This can be used to let end-users know something is happening, or even just to debug your chain. You can stream intermediate results, and it’s available on every LangServe server.
-
Input and output schemas Input and output schemas give every LCEL chain Pydantic and JSONSchema schemas inferred from the structure of your chain. This can be used for validation of inputs and outputs, and is an integral part of LangServe.
-
Seamless LangSmith tracing As your chains get more and more complex, it becomes increasingly important to understand what exactly is happening at every step. With LCEL, all steps are automatically logged to LangSmith for maximum observability and debuggability.
LCEL aims to provide consistency around behavior and customization over legacy subclassed chains such as LLMChain and
ConversationalRetrievalChain. Many of these legacy chains hide important details like prompts, and as a wider variety
of viable models emerge, customization has become more and more important.
If you are currently using one of these legacy chains, please see this guide for guidance on how to migrate.
For guides on how to do specific tasks with LCEL, check out the relevant how-to guides.
Runnable interface
To make it as easy as possible to create custom chains, we've implemented a "Runnable" protocol. Many LangChain components implement the Runnable protocol, including chat models, LLMs, output parsers, retrievers, prompt templates, and more. There are also several useful primitives for working with runnables, which you can read about below.
This is a standard interface, which makes it easy to define custom chains as well as invoke them in a standard way. The standard interface includes:
stream: stream back chunks of the responseinvoke: call the chain on an inputbatch: call the chain on a list of inputs
These also have corresponding async methods that should be used with asyncio await syntax for concurrency:
astream: stream back chunks of the response asyncainvoke: call the chain on an input asyncabatch: call the chain on a list of inputs asyncastream_log: stream back intermediate steps as they happen, in addition to the final responseastream_events: beta stream events as they happen in the chain (introduced inlangchain-core0.1.14)
The input type and output type varies by component:
| Component | Input Type | Output Type |
|---|---|---|
| Prompt | Dictionary | PromptValue |
| ChatModel | Single string, list of chat messages or a PromptValue | ChatMessage |
| LLM | Single string, list of chat messages or a PromptValue | String |
| OutputParser | The output of an LLM or ChatModel | Depends on the parser |
| Retriever | Single string | List of Documents |
| Tool | Single string or dictionary, depending on the tool | Depends on the tool |
All runnables expose input and output schemas to inspect the inputs and outputs:
input_schema: an input Pydantic model auto-generated from the structure of the Runnableoutput_schema: an output Pydantic model auto-generated from the structure of the Runnable
Components
LangChain provides standard, extendable interfaces and external integrations for various components useful for building with LLMs. Some components LangChain implements, some components we rely on third-party integrations for, and others are a mix.
Chat models
Language models that use a sequence of messages as inputs and return chat messages as outputs (as opposed to using plain text).
These are traditionally newer models (older models are generally LLMs, see below).
Chat models support the assignment of distinct roles to conversation messages, helping to distinguish messages from the AI, users, and instructions such as system messages.
Although the underlying models are messages in, message out, the LangChain wrappers also allow these models to take a string as input. This means you can easily use chat models in place of LLMs.
When a string is passed in as input, it is converted to a HumanMessage and then passed to the underlying model.
LangChain does not host any Chat Models, rather we rely on third party integrations.
We have some standardized parameters when constructing ChatModels:
model: the name of the modeltemperature: the sampling temperaturetimeout: request timeoutmax_tokens: max tokens to generatestop: default stop sequencesmax_retries: max number of times to retry requestsapi_key: API key for the model providerbase_url: endpoint to send requests to
Some important things to note:
- standard params only apply to model providers that expose parameters with the intended functionality. For example, some providers do not expose a configuration for maximum output tokens, so max_tokens can't be supported on these.
- standard params are currently only enforced on integrations that have their own integration packages (e.g.
langchain-openai,langchain-anthropic, etc.), they're not enforced on models inlangchain-community.
ChatModels also accept other parameters that are specific to that integration. To find all the parameters supported by a ChatModel head to the API reference for that model.
Some chat models have been fine-tuned for tool calling and provide a dedicated API for it. Generally, such models are better at tool calling than non-fine-tuned models, and are recommended for use cases that require tool calling. Please see the tool calling section for more information.
For specifics on how to use chat models, see the relevant how-to guides here.
Multimodality
Some chat models are multimodal, accepting images, audio and even video as inputs. These are still less common, meaning model providers haven't standardized on the "best" way to define the API. Multimodal outputs are even less common. As such, we've kept our multimodal abstractions fairly light weight and plan to further solidify the multimodal APIs and interaction patterns as the field matures.
In LangChain, most chat models that support multimodal inputs also accept those values in OpenAI's content blocks format. So far this is restricted to image inputs. For models like Gemini which support video and other bytes input, the APIs also support the native, model-specific representations.
For specifics on how to use multimodal models, see the relevant how-to guides here.
For a full list of LangChain model providers with multimodal models, check out this table.
LLMs
Pure text-in/text-out LLMs tend to be older or lower-level. Many new popular models are best used as chat completion models, even for non-chat use cases.
You are probably looking for the section above instead.
Language models that takes a string as input and returns a string. These are traditionally older models (newer models generally are Chat Models, see above).
Although the underlying models are string in, string out, the LangChain wrappers also allow these models to take messages as input. This gives them the same interface as Chat Models. When messages are passed in as input, they will be formatted into a string under the hood before being passed to the underlying model.
LangChain does not host any LLMs, rather we rely on third party integrations.
For specifics on how to use LLMs, see the how-to guides.
Messages
Some language models take a list of messages as input and return a message.
There are a few different types of messages.
All messages have a role, content, and response_metadata property.
The role describes WHO is saying the message. The standard roles are "user", "assistant", "system", and "tool".
LangChain has different message classes for different roles.
The content property describes the content of the message.
This can be a few different things:
- A string (most models deal with this type of content)
- A List of dictionaries (this is used for multimodal input, where the dictionary contains information about that input type and that input location)
Optionally, messages can have a name property which allows for differentiating between multiple speakers with the same role.
For example, if there are two users in the chat history it can be useful to differentiate between them. Not all models support this.
HumanMessage
This represents a message with role "user".
AIMessage
This represents a message with role "assistant". In addition to the content property, these messages also have:
response_metadata
The response_metadata property contains additional metadata about the response. The data here is often specific to each model provider.
This is where information like log-probs and token usage may be stored.
tool_calls
These represent a decision from a language model to call a tool. They are included as part of an AIMessage output.
They can be accessed from there with the .tool_calls property.
This property returns a list of ToolCalls. A ToolCall is a dictionary with the following arguments:
name: The name of the tool that should be called.args: The arguments to that tool.id: The id of that tool call.
SystemMessage
This represents a message with role "system", which tells the model how to behave. Not every model provider supports this.
ToolMessage
This represents a message with role "tool", which contains the result of calling a tool. In addition to role and content, this message has:
- a
tool_call_idfield which conveys the id of the call to the tool that was called to produce this result. - an
artifactfield which can be used to pass along arbitrary artifacts of the tool execution which are useful to track but which should not be sent to the model.
With most chat models, a ToolMessage can only appear in the chat history after an AIMessage that has a populated tool_calls field.
(Legacy) FunctionMessage
This is a legacy message type, corresponding to OpenAI's legacy function-calling API. ToolMessage should be used instead to correspond to the updated tool-calling API.
This represents the result of a function call. In addition to role and content, this message has a name parameter which conveys the name of the function that was called to produce this result.
Prompt templates
Prompt templates help to translate user input and parameters into instructions for a language model. This can be used to guide a model's response, helping it understand the context and generate relevant and coherent language-based output.
Prompt Templates take as input a dictionary, where each key represents a variable in the prompt template to fill in.
Prompt Templates output a PromptValue. This PromptValue can be passed to an LLM or a ChatModel, and can also be cast to a string or a list of messages. The reason this PromptValue exists is to make it easy to switch between strings and messages.
There are a few different types of prompt templates:
String PromptTemplates
These prompt templates are used to format a single string, and generally are used for simpler inputs. For example, a common way to construct and use a PromptTemplate is as follows:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})
ChatPromptTemplates
These prompt templates are used to format a list of messages. These "templates" consist of a list of templates themselves. For example, a common way to construct and use a ChatPromptTemplate is as follows:
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"})
In the above example, this ChatPromptTemplate will construct two messages when called.
The first is a system message, that has no variables to format.
The second is a HumanMessage, and will be formatted by the topic variable the user passes in.
MessagesPlaceholder
This prompt template is responsible for adding a list of messages in a particular place. In the above ChatPromptTemplate, we saw how we could format two messages, each one a string. But what if we wanted the user to pass in a list of messages that we would slot into a particular spot? This is how you use MessagesPlaceholder.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs")
])
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})
This will produce a list of two messages, the first one being a system message, and the second one being the HumanMessage we passed in. If we had passed in 5 messages, then it would have produced 6 messages in total (the system message plus the 5 passed in). This is useful for letting a list of messages be slotted into a particular spot.
An alternative way to accomplish the same thing without using the MessagesPlaceholder class explicitly is:
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("placeholder", "{msgs}") # <-- This is the changed part
])
For specifics on how to use prompt templates, see the relevant how-to guides here.
Example selectors
One common prompting technique for achieving better performance is to include examples as part of the prompt. This is known as few-shot prompting. This gives the language model concrete examples of how it should behave. Sometimes these examples are hardcoded into the prompt, but for more advanced situations it may be nice to dynamically select them. Example Selectors are classes responsible for selecting and then formatting examples into prompts.
For specifics on how to use example selectors, see the relevant how-to guides here.
Output parsers
The information here refers to parsers that take a text output from a model try to parse it into a more structured representation. More and more models are supporting function (or tool) calling, which handles this automatically. It is recommended to use function/tool calling rather than output parsing. See documentation for that here.
Output parser is responsible for taking the output of a model and transforming it to a more suitable format for downstream tasks.
Useful when you are using LLMs to generate structured data, or to normalize output from chat models and LLMs.
LangChain has lots of different types of output parsers. This is a list of output parsers LangChain supports. The table below has various pieces of information:
- Name: The name of the output parser
- Supports Streaming: Whether the output parser supports streaming.
- Has Format Instructions: Whether the output parser has format instructions. This is generally available except when (a) the desired schema is not specified in the prompt but rather in other parameters (like OpenAI function calling), or (b) when the OutputParser wraps another OutputParser.
- Calls LLM: Whether this output parser itself calls an LLM. This is usually only done by output parsers that attempt to correct misformatted output.
- Input Type: Expected input type. Most output parsers work on both strings and messages, but some (like OpenAI Functions) need a message with specific kwargs.
- Output Type: The output type of the object returned by the parser.
- Description: Our commentary on this output parser and when to use it.
| Name | Supports Streaming | Has Format Instructions | Calls LLM | Input Type | Output Type | Description |
|---|---|---|---|---|---|---|
| JSON | ✅ | ✅ | str | Message | JSON object | Returns a JSON object as specified. You can specify a Pydantic model and it will return JSON for that model. Probably the most reliable output parser for getting structured data that does NOT use function calling. | |
| XML | ✅ | ✅ | str | Message | dict | Returns a dictionary of tags. Use when XML output is needed. Use with models that are good at writing XML (like Anthropic's). | |
| CSV | ✅ | ✅ | str | Message | List[str] | Returns a list of comma separated values. | |
| OutputFixing | ✅ | str | Message | Wraps another output parser. If that output parser errors, then this will pass the error message and the bad output to an LLM and ask it to fix the output. | |||
| RetryWithError | ✅ | str | Message | Wraps another output parser. If that output parser errors, then this will pass the original inputs, the bad output, and the error message to an LLM and ask it to fix it. Compared to OutputFixingParser, this one also sends the original instructions. | |||
| Pydantic | ✅ | str | Message | pydantic.BaseModel | Takes a user defined Pydantic model and returns data in that format. | ||
| YAML | ✅ | str | Message | pydantic.BaseModel | Takes a user defined Pydantic model and returns data in that format. Uses YAML to encode it. | ||
| PandasDataFrame | ✅ | str | Message | dict | Useful for doing operations with pandas DataFrames. | ||
| Enum | ✅ | str | Message | Enum | Parses response into one of the provided enum values. | ||
| Datetime | ✅ | str | Message | datetime.datetime | Parses response into a datetime string. | ||
| Structured | ✅ | str | Message | Dict[str, str] | An output parser that returns structured information. It is less powerful than other output parsers since it only allows for fields to be strings. This can be useful when you are working with smaller LLMs. |
For specifics on how to use output parsers, see the relevant how-to guides here.
Chat history
Most LLM applications have a conversational interface. An essential component of a conversation is being able to refer to information introduced earlier in the conversation. At bare minimum, a conversational system should be able to access some window of past messages directly.
The concept of ChatHistory refers to a class in LangChain which can be used to wrap an arbitrary chain.
This ChatHistory will keep track of inputs and outputs of the underlying chain, and append them as messages to a message database.
Future interactions will then load those messages and pass them into the chain as part of the input.
Documents
A Document object in LangChain contains information about some data. It has two attributes:
page_content: str: The content of this document. Currently is only a string.metadata: dict: Arbitrary metadata associated with this document. Can track the document id, file name, etc.
Document loaders
These classes load Document objects. LangChain has hundreds of integrations with various data sources to load data from: Slack, Notion, Google Drive, etc.
Each DocumentLoader has its own specific parameters, but they can all be invoked in the same way with the .load method.
An example use case is as follows:
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(
... # <-- Integration specific parameters here
)
data = loader.load()
For specifics on how to use document loaders, see the relevant how-to guides here.
Text splitters
Once you've loaded documents, you'll often want to transform them to better suit your application. The simplest example is you may want to split a long document into smaller chunks that can fit into your model's context window. LangChain has a number of built-in document transformers that make it easy to split, combine, filter, and otherwise manipulate documents.
When you want to deal with long pieces of text, it is necessary to split up that text into chunks. As simple as this sounds, there is a lot of potential complexity here. Ideally, you want to keep the semantically related pieces of text together. What "semantically related" means could depend on the type of text. This notebook showcases several ways to do that.
At a high level, text splitters work as following:
- Split the text up into small, semantically meaningful chunks (often sentences).
- Start combining these small chunks into a larger chunk until you reach a certain size (as measured by some function).
- Once you reach that size, make that chunk its own piece of text and then start creating a new chunk of text with some overlap (to keep context between chunks).
That means there are two different axes along which you can customize your text splitter:
- How the text is split
- How the chunk size is measured
For specifics on how to use text splitters, see the relevant how-to guides here.
Embedding models
Embedding models create a vector representation of a piece of text. You can think of a vector as an array of numbers that captures the semantic meaning of the text. By representing the text in this way, you can perform mathematical operations that allow you to do things like search for other pieces of text that are most similar in meaning. These natural language search capabilities underpin many types of context retrieval, where we provide an LLM with the relevant data it needs to effectively respond to a query.
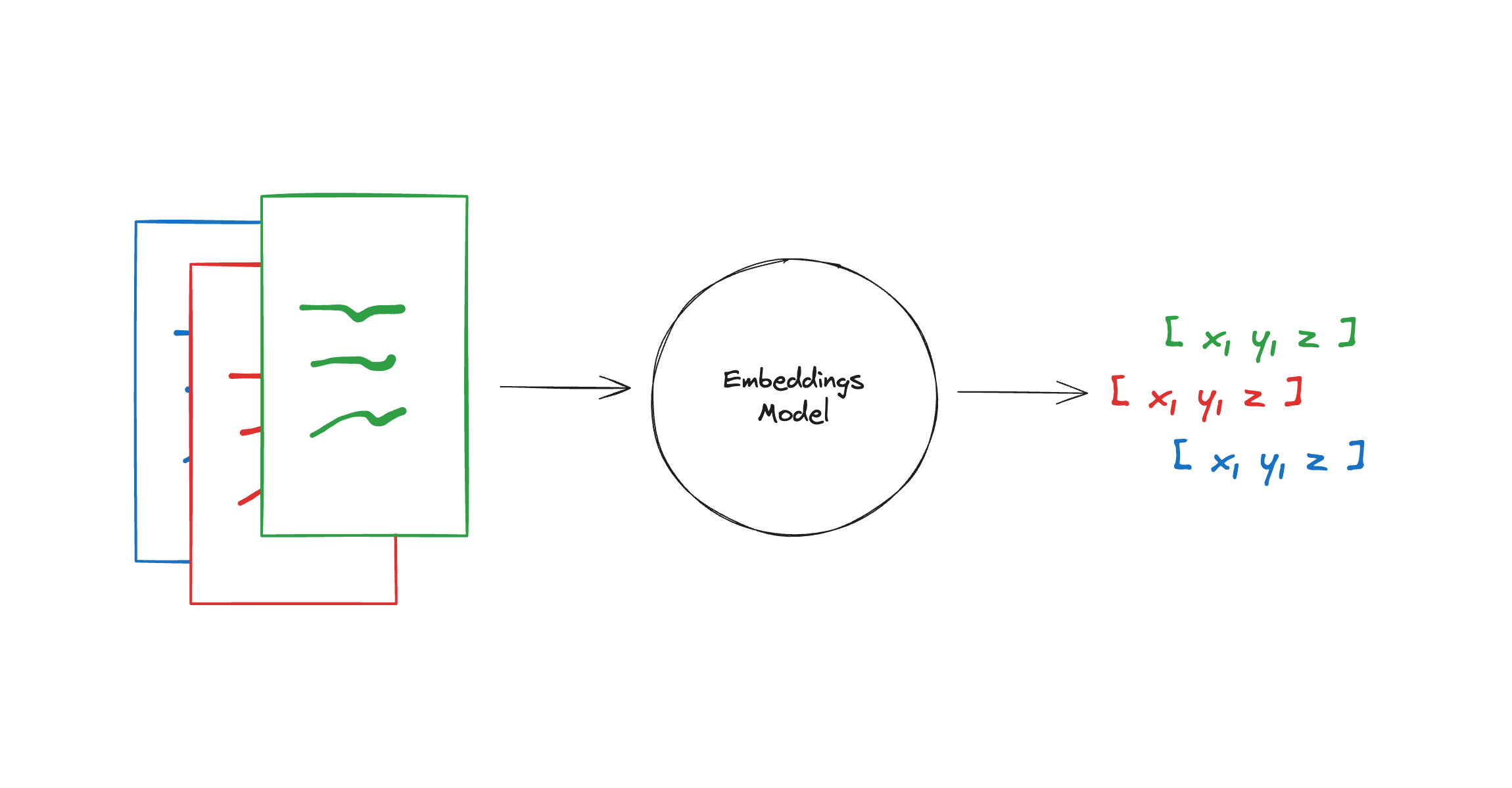
The Embeddings class is a class designed for interfacing with text embedding models. There are many different embedding model providers (OpenAI, Cohere, Hugging Face, etc) and local models, and this class is designed to provide a standard interface for all of them.
The base Embeddings class in LangChain provides two methods: one for embedding documents and one for embedding a query. The former takes as input multiple texts, while the latter takes a single text. The reason for having these as two separate methods is that some embedding providers have different embedding methods for documents (to be searched over) vs queries (the search query itself).
For specifics on how to use embedding models, see the relevant how-to guides here.
Vector stores
One of the most common ways to store and search over unstructured data is to embed it and store the resulting embedding vectors, and then at query time to embed the unstructured query and retrieve the embedding vectors that are 'most similar' to the embedded query. A vector store takes care of storing embedded data and performing vector search for you.
Most vector stores can also store metadata about embedded vectors and support filtering on that metadata before similarity search, allowing you more control over returned documents.
Vector stores can be converted to the retriever interface by doing:
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
For specifics on how to use vector stores, see the relevant how-to guides here.
Retrievers
A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Retrievers can be created from vector stores, but are also broad enough to include Wikipedia search and Amazon Kendra.
Retrievers accept a string query as input and return a list of Document's as output.
For specifics on how to use retrievers, see the relevant how-to guides here.
Key-value stores
For some techniques, such as indexing and retrieval with multiple vectors per document or caching embeddings, having a form of key-value (KV) storage is helpful.
LangChain includes a BaseStore interface,
which allows for storage of arbitrary data. However, LangChain components that require KV-storage accept a
more specific BaseStore[str, bytes] instance that stores binary data (referred to as a ByteStore), and internally take care of
encoding and decoding data for their specific needs.
This means that as a user, you only need to think about one type of store rather than different ones for different types of data.
Interface
All BaseStores support the following interface. Note that the interface allows
for modifying multiple key-value pairs at once:
mget(key: Sequence[str]) -> List[Optional[bytes]]: get the contents of multiple keys, returningNoneif the key does not existmset(key_value_pairs: Sequence[Tuple[str, bytes]]) -> None: set the contents of multiple keysmdelete(key: Sequence[str]) -> None: delete multiple keysyield_keys(prefix: Optional[str] = None) -> Iterator[str]: yield all keys in the store, optionally filtering by a prefix
For key-value store implementations, see this section.
Tools
Tools are utilities designed to be called by a model: their inputs are designed to be generated by models, and their outputs are designed to be passed back to models. Tools are needed whenever you want a model to control parts of your code or call out to external APIs.
A tool consists of:
- The
nameof the tool. - A
descriptionof what the tool does. - A
JSON schemadefining the inputs to the tool. - A
function(and, optionally, an async variant of the function).
When a tool is bound to a model, the name, description and JSON schema are provided as context to the model. Given a list of tools and a set of instructions, a model can request to call one or more tools with specific inputs. Typical usage may look like the following:
tools = [...] # Define a list of tools
llm_with_tools = llm.bind_tools(tools)
ai_msg = llm_with_tools.invoke("do xyz...")
# -> AIMessage(tool_calls=[ToolCall(...), ...], ...)
The AIMessage returned from the model MAY have tool_calls associated with it.
Read this guide for more information on what the response type may look like.
Once the chosen tools are invoked, the results can be passed back to the model so that it can complete whatever task it's performing. There are generally two different ways to invoke the tool and pass back the response:
Invoke with just the arguments
When you invoke a tool with just the arguments, you will get back the raw tool output (usually a string). This generally looks like:
# You will want to previously check that the LLM returned tool calls
tool_call = ai_msg.tool_calls[0]
# ToolCall(args={...}, id=..., ...)
tool_output = tool.invoke(tool_call["args"])
tool_message = ToolMessage(
content=tool_output,
tool_call_id=tool_call["id"],
name=tool_call["name"]
)
Note that the content field will generally be passed back to the model.
If you do not want the raw tool response to be passed to the model, but you still want to keep it around,
you can transform the tool output but also pass it as an artifact (read more about ToolMessage.artifact here)
... # Same code as above
response_for_llm = transform(response)
tool_message = ToolMessage(
content=response_for_llm,
tool_call_id=tool_call["id"],
name=tool_call["name"],
artifact=tool_output
)
Invoke with ToolCall
The other way to invoke a tool is to call it with the full ToolCall that was generated by the model.
When you do this, the tool will return a ToolMessage.
The benefits of this are that you don't have to write the logic yourself to transform the tool output into a ToolMessage.
This generally looks like:
tool_call = ai_msg.tool_calls[0]
# -> ToolCall(args={...}, id=..., ...)
tool_message = tool.invoke(tool_call)
# -> ToolMessage(
# content="tool result foobar...",
# tool_call_id=...,
# name="tool_name"
# )
If you are invoking the tool this way and want to include an artifact for the ToolMessage, you will need to have the tool return two things. Read more about defining tools that return artifacts here.
Best practices
When designing tools to be used by a model, it is important to keep in mind that:
- Chat models that have explicit tool-calling APIs will be better at tool calling than non-fine-tuned models.
- Models will perform better if the tools have well-chosen names, descriptions, and JSON schemas. This is another form of prompt engineering.
- Simple, narrowly scoped tools are easier for models to use than complex tools.
Related
For specifics on how to use tools, see the tools how-to guides.
To use a pre-built tool, see the tool integration docs.
Toolkits
Toolkits are collections of tools that are designed to be used together for specific tasks. They have convenient loading methods.
All Toolkits expose a get_tools method which returns a list of tools.
You can therefore do:
# Initialize a toolkit
toolkit = ExampleTookit(...)
# Get list of tools
tools = toolkit.get_tools()
Agents
By themselves, language models can't take actions - they just output text. A big use case for LangChain is creating agents. Agents are systems that use an LLM as a reasoning engine to determine which actions to take and what the inputs to those actions should be. The results of those actions can then be fed back into the agent and it determine whether more actions are needed, or whether it is okay to finish.
LangGraph is an extension of LangChain specifically aimed at creating highly controllable and customizable agents. Please check out that documentation for a more in depth overview of agent concepts.
There is a legacy agent concept in LangChain that we are moving towards deprecating: AgentExecutor.
AgentExecutor was essentially a runtime for agents.
It was a great place to get started, however, it was not flexible enough as you started to have more customized agents.
In order to solve that we built LangGraph to be this flexible, highly-controllable runtime.
If you are still using AgentExecutor, do not fear: we still have a guide on how to use AgentExecutor. It is recommended, however, that you start to transition to LangGraph. In order to assist in this, we have put together a transition guide on how to do so.
ReAct agents
One popular architecture for building agents is ReAct. ReAct combines reasoning and acting in an iterative process - in fact the name "ReAct" stands for "Reason" and "Act".
The general flow looks like this:
- The model will "think" about what step to take in response to an input and any previous observations.
- The model will then choose an action from available tools (or choose to respond to the user).
- The model will generate arguments to that tool.
- The agent runtime (executor) will parse out the chosen tool and call it with the generated arguments.
- The executor will return the results of the tool call back to the model as an observation.
- This process repeats until the agent chooses to respond.
There are general prompting based implementations that do not require any model-specific features, but the most reliable implementations use features like tool calling to reliably format outputs and reduce variance.
Please see the LangGraph documentation for more information, or this how-to guide for specific information on migrating to LangGraph.
Callbacks
LangChain provides a callbacks system that allows you to hook into the various stages of your LLM application. This is useful for logging, monitoring, streaming, and other tasks.
You can subscribe to these events by using the callbacks argument available throughout the API. This argument is list of handler objects, which are expected to implement one or more of the methods described below in more detail.
Callback Events
| Event | Event Trigger | Associated Method |
|---|---|---|
| Chat model start | When a chat model starts | on_chat_model_start |
| LLM start | When a llm starts | on_llm_start |
| LLM new token | When an llm OR chat model emits a new token | on_llm_new_token |
| LLM ends | When an llm OR chat model ends | on_llm_end |
| LLM errors | When an llm OR chat model errors | on_llm_error |
| Chain start | When a chain starts running | on_chain_start |
| Chain end | When a chain ends | on_chain_end |
| Chain error | When a chain errors | on_chain_error |
| Tool start | When a tool starts running | on_tool_start |
| Tool end | When a tool ends | on_tool_end |
| Tool error | When a tool errors | on_tool_error |
| Agent action | When an agent takes an action | on_agent_action |
| Agent finish | When an agent ends | on_agent_finish |
| Retriever start | When a retriever starts | on_retriever_start |
| Retriever end | When a retriever ends | on_retriever_end |
| Retriever error | When a retriever errors | on_retriever_error |
| Text | When arbitrary text is run | on_text |
| Retry | When a retry event is run | on_retry |
Callback handlers
Callback handlers can either be sync or async:
- Sync callback handlers implement the BaseCallbackHandler interface.
- Async callback handlers implement the AsyncCallbackHandler interface.
During run-time LangChain configures an appropriate callback manager (e.g., CallbackManager or AsyncCallbackManager which will be responsible for calling the appropriate method on each "registered" callback handler when the event is triggered.
Passing callbacks
The callbacks property is available on most objects throughout the API (Models, Tools, Agents, etc.) in two different places:
- Request time callbacks: Passed at the time of the request in addition to the input data.
Available on all standard
Runnableobjects. These callbacks are INHERITED by all children of the object they are defined on. For example,chain.invoke({"number": 25}, {"callbacks": [handler]}). - Constructor callbacks:
chain = TheNameOfSomeChain(callbacks=[handler]). These callbacks are passed as arguments to the constructor of the object. The callbacks are scoped only to the object they are defined on, and are not inherited by any children of the object.
Constructor callbacks are scoped only to the object they are defined on. They are not inherited by children of the object.
If you're creating a custom chain or runnable, you need to remember to propagate request time callbacks to any child objects.
Any RunnableLambda, a RunnableGenerator, or Tool that invokes other runnables
and is running async in python<=3.10, will have to propagate callbacks to child
objects manually. This is because LangChain cannot automatically propagate
callbacks to child objects in this case.
This is a common reason why you may fail to see events being emitted from custom runnables or tools.
For specifics on how to use callbacks, see the relevant how-to guides here.
Techniques
Streaming
Individual LLM calls often run for much longer than traditional resource requests. This compounds when you build more complex chains or agents that require multiple reasoning steps.
Fortunately, LLMs generate output iteratively, which means it's possible to show sensible intermediate results before the final response is ready. Consuming output as soon as it becomes available has therefore become a vital part of the UX around building apps with LLMs to help alleviate latency issues, and LangChain aims to have first-class support for streaming.
Below, we'll discuss some concepts and considerations around streaming in LangChain.
.stream() and .astream()
Most modules in LangChain include the .stream() method (and the equivalent .astream() method for async environments) as an ergonomic streaming interface.
.stream() returns an iterator, which you can consume with a simple for loop. Here's an example with a chat model:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
for chunk in model.stream("what color is the sky?"):
print(chunk.content, end="|", flush=True)
For models (or other components) that don't support streaming natively, this iterator would just yield a single chunk, but
you could still use the same general pattern when calling them. Using .stream() will also automatically call the model in streaming mode
without the need to provide additional config.
The type of each outputted chunk depends on the type of component - for example, chat models yield AIMessageChunks.
Because this method is part of LangChain Expression Language,
you can handle formatting differences from different outputs using an output parser to transform
each yielded chunk.
You can check out this guide for more detail on how to use .stream().
.astream_events()
While the .stream() method is intuitive, it can only return the final generated value of your chain. This is fine for single LLM calls,
but as you build more complex chains of several LLM calls together, you may want to use the intermediate values of
the chain alongside the final output - for example, returning sources alongside the final generation when building a chat
over documents app.
There are ways to do this using callbacks, or by constructing your chain in such a way that it passes intermediate
values to the end with something like chained .assign() calls, but LangChain also includes an
.astream_events() method that combines the flexibility of callbacks with the ergonomics of .stream(). When called, it returns an iterator
which yields various types of events that you can filter and process according
to the needs of your project.
Here's one small example that prints just events containing streamed chat model output:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
parser = StrOutputParser()
chain = prompt | model | parser
async for event in chain.astream_events({"topic": "parrot"}, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event, end="|", flush=True)
You can roughly think of it as an iterator over callback events (though the format differs) - and you can use it on almost all LangChain components!
See this guide for more detailed information on how to use .astream_events(),
including a table listing available events.
Callbacks
The lowest level way to stream outputs from LLMs in LangChain is via the callbacks system. You can pass a
callback handler that handles the on_llm_new_token event into LangChain components. When that component is invoked, any
LLM or chat model contained in the component calls
the callback with the generated token. Within the callback, you could pipe the tokens into some other destination, e.g. a HTTP response.
You can also handle the on_llm_end event to perform any necessary cleanup.
You can see this how-to section for more specifics on using callbacks.
Callbacks were the first technique for streaming introduced in LangChain. While powerful and generalizable, they can be unwieldy for developers. For example:
- You need to explicitly initialize and manage some aggregator or other stream to collect results.
- The execution order isn't explicitly guaranteed, and you could theoretically have a callback run after the
.invoke()method finishes. - Providers would often make you pass an additional parameter to stream outputs instead of returning them all at once.
- You would often ignore the result of the actual model call in favor of callback results.
Tokens
The unit that most model providers use to measure input and output is via a unit called a token. Tokens are the basic units that language models read and generate when processing or producing text. The exact definition of a token can vary depending on the specific way the model was trained - for instance, in English, a token could be a single word like "apple", or a part of a word like "app".
When you send a model a prompt, the words and characters in the prompt are encoded into tokens using a tokenizer.
The model then streams back generated output tokens, which the tokenizer decodes into human-readable text.
The below example shows how OpenAI models tokenize LangChain is cool!:
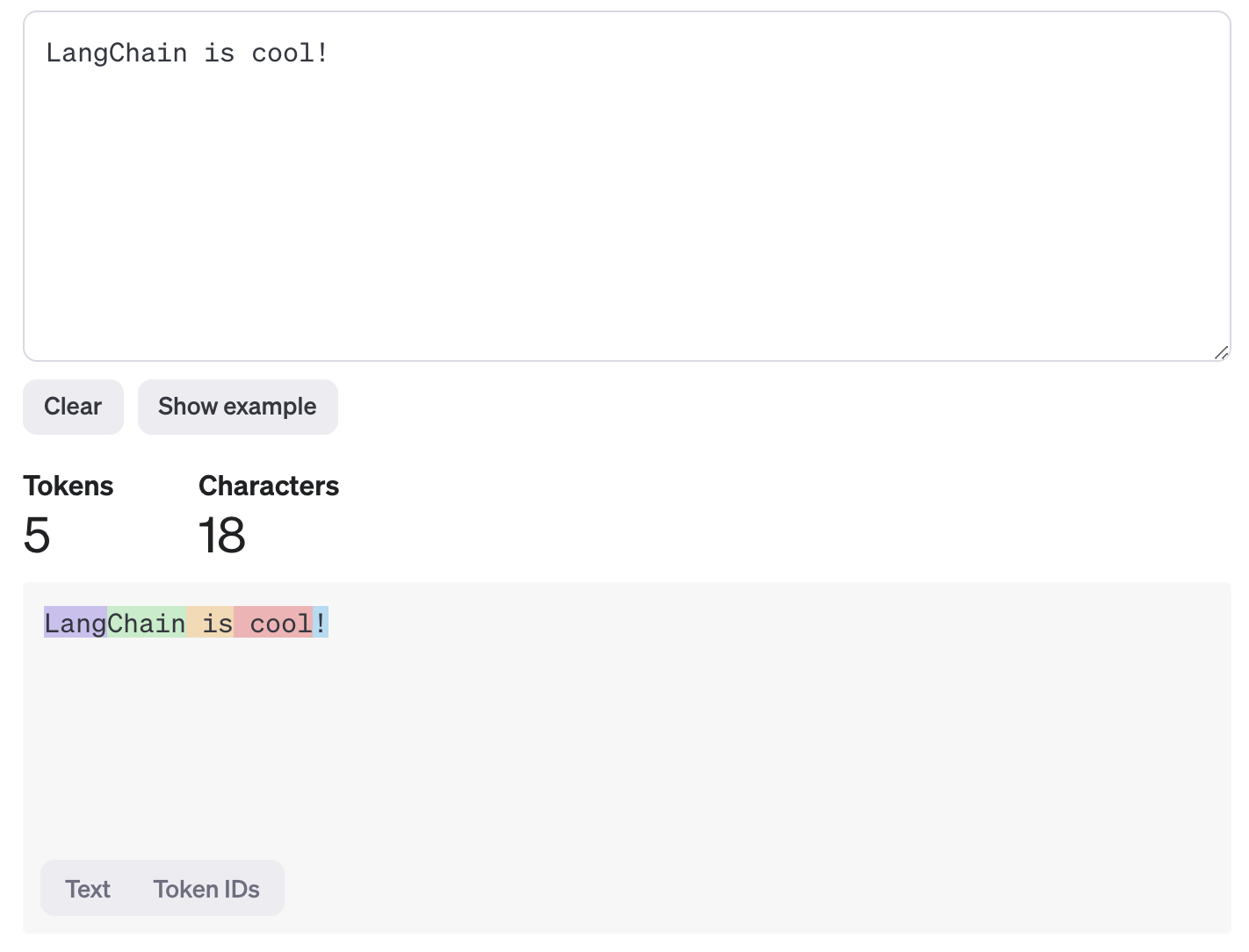
You can see that it gets split into 5 different tokens, and that the boundaries between tokens are not exactly the same as word boundaries.
The reason language models use tokens rather than something more immediately intuitive like "characters" has to do with how they process and understand text. At a high-level, language models iteratively predict their next generated output based on the initial input and their previous generations. Training the model using tokens language models to handle linguistic units (like words or subwords) that carry meaning, rather than individual characters, which makes it easier for the model to learn and understand the structure of the language, including grammar and context. Furthermore, using tokens can also improve efficiency, since the model processes fewer units of text compared to character-level processing.
Function/tool calling
We use the term tool calling interchangeably with function calling. Although
function calling is sometimes meant to refer to invocations of a single function,
we treat all models as though they can return multiple tool or function calls in
each message.
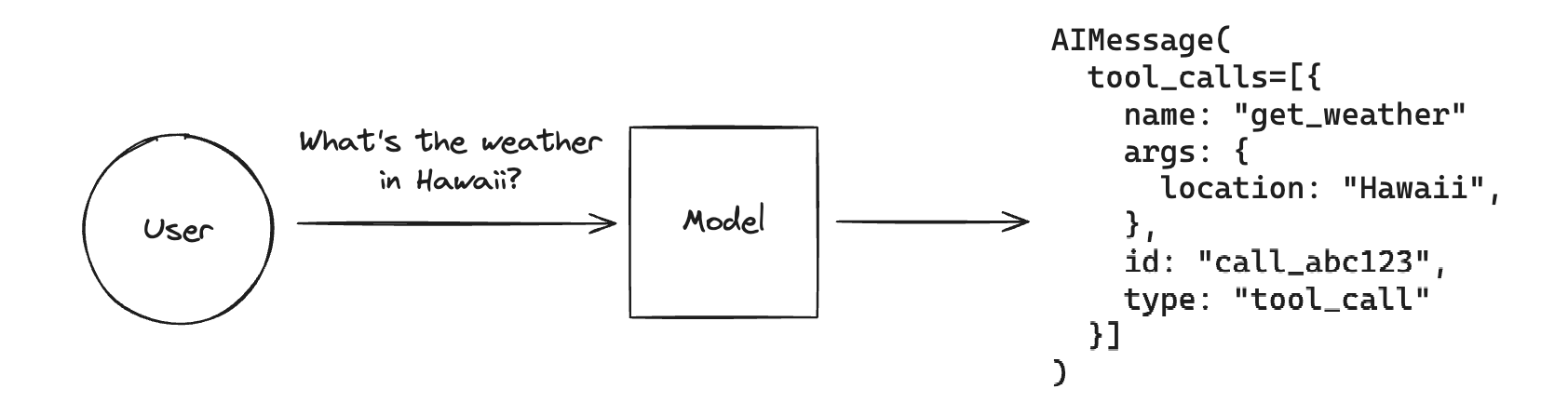
Tool calling allows a chat model to respond to a given prompt by generating output that matches a user-defined schema.
While the name implies that the model is performing some action, this is actually not the case! The model only generates the arguments to a tool, and actually running the tool (or not) is up to the user. One common example where you wouldn't want to call a function with the generated arguments is if you want to extract structured output matching some schema from unstructured text. You would give the model an "extraction" tool that takes parameters matching the desired schema, then treat the generated output as your final result.
Tool calling is not universal, but is supported by many popular LLM providers, including Anthropic, Cohere, Google, Mistral, OpenAI, and even for locally-running models via Ollama.
LangChain provides a standardized interface for tool calling that is consistent across different models.
The standard interface consists of:
ChatModel.bind_tools(): a method for specifying which tools are available for a model to call. This method accepts LangChain tools as well as Pydantic objects.AIMessage.tool_calls: an attribute on theAIMessagereturned from the model for accessing the tool calls requested by the model.
Tool usage
After the model calls tools, you can use the tool by invoking it, then passing the arguments back to the model.
LangChain provides the Tool abstraction to help you handle this.
The general flow is this:
- Generate tool calls with a chat model in response to a query.
- Invoke the appropriate tools using the generated tool call as arguments.
- Format the result of the tool invocations as
ToolMessages. - Pass the entire list of messages back to the model so that it can generate a final answer (or call more tools).
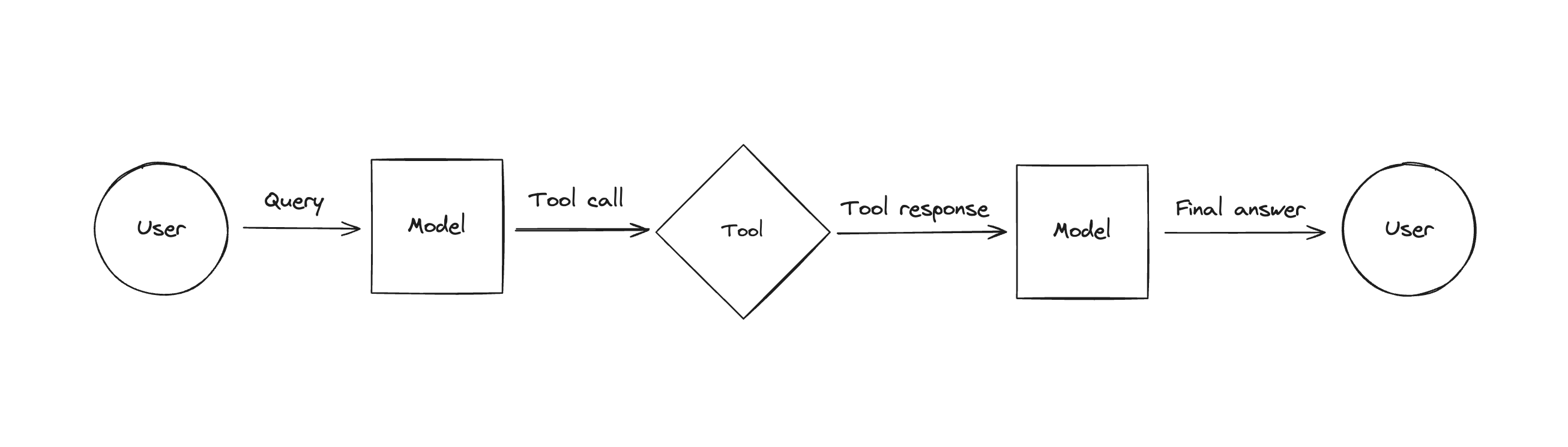
This is how tool calling agents perform tasks and answer queries.
Check out some more focused guides below:
- How to use chat models to call tools
- How to pass tool outputs to chat models
- Building an agent with LangGraph
Structured output
LLMs are capable of generating arbitrary text. This enables the model to respond appropriately to a wide range of inputs, but for some use-cases, it can be useful to constrain the LLM's output to a specific format or structure. This is referred to as structured output.
For example, if the output is to be stored in a relational database, it is much easier if the model generates output that adheres to a defined schema or format. Extracting specific information from unstructured text is another case where this is particularly useful. Most commonly, the output format will be JSON, though other formats such as YAML can be useful too. Below, we'll discuss a few ways to get structured output from models in LangChain.
.with_structured_output()
For convenience, some LangChain chat models support a .with_structured_output()
method. This method only requires a schema as input, and returns a dict or Pydantic object.
Generally, this method is only present on models that support one of the more advanced methods described below,
and will use one of them under the hood. It takes care of importing a suitable output parser and
formatting the schema in the right format for the model.
Here's an example:
from typing import Optional
from pydantic import BaseModel, Field
class Joke(BaseModel):
"""Joke to tell user."""
setup: str = Field(description="The setup of the joke")
punchline: str = Field(description="The punchline to the joke")
rating: Optional[int] = Field(description="How funny the joke is, from 1 to 10")
structured_llm = llm.with_structured_output(Joke)
structured_llm.invoke("Tell me a joke about cats")
Joke(setup='Why was the cat sitting on the computer?', punchline='To keep an eye on the mouse!', rating=None)
We recommend this method as a starting point when working with structured output:
- It uses other model-specific features under the hood, without the need to import an output parser.
- For the models that use tool calling, no special prompting is needed.
- If multiple underlying techniques are supported, you can supply a
methodparameter to toggle which one is used.
You may want or need to use other techniques if:
- The chat model you are using does not support tool calling.
- You are working with very complex schemas and the model is having trouble generating outputs that conform.
For more information, check out this how-to guide.
You can also check out this table for a list of models that support
with_structured_output().
Raw prompting
The most intuitive way to get a model to structure output is to ask nicely. In addition to your query, you can give instructions describing what kind of output you'd like, then parse the output using an output parser to convert the raw model message or string output into something more easily manipulated.
The biggest benefit to raw prompting is its flexibility:
- Raw prompting does not require any special model features, only sufficient reasoning capability to understand the passed schema.
- You can prompt for any format you'd like, not just JSON. This can be useful if the model you are using is more heavily trained on a certain type of data, such as XML or YAML.
However, there are some drawbacks too:
- LLMs are non-deterministic, and prompting a LLM to consistently output data in the exactly correct format for smooth parsing can be surprisingly difficult and model-specific.
- Individual models have quirks depending on the data they were trained on, and optimizing prompts can be quite difficult. Some may be better at interpreting JSON schema, others may be best with TypeScript definitions, and still others may prefer XML.
While features offered by model providers may increase reliability, prompting techniques remain important for tuning your results no matter which method you choose.
JSON mode
Some models, such as Mistral, OpenAI, Together AI and Ollama, support a feature called JSON mode, usually enabled via config.
When enabled, JSON mode will constrain the model's output to always be some sort of valid JSON.
Often they require some custom prompting, but it's usually much less burdensome than completely raw prompting and
more along the lines of, "you must always return JSON". The output also generally easier to parse.
It's also generally simpler to use directly and more commonly available than tool calling, and can give more flexibility around prompting and shaping results than tool calling.
Here's an example:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers.json import SimpleJsonOutputParser
model = ChatOpenAI(
model="gpt-4o",
model_kwargs={ "response_format": { "type": "json_object" } },
)
prompt = ChatPromptTemplate.from_template(
"Answer the user's question to the best of your ability."
'You must always output a JSON object with an "answer" key and a "followup_question" key.'
"{question}"
)
chain = prompt | model | SimpleJsonOutputParser()
chain.invoke({ "question": "What is the powerhouse of the cell?" })
{'answer': 'The powerhouse of the cell is the mitochondrion. It is responsible for producing energy in the form of ATP through cellular respiration.',
'followup_question': 'Would you like to know more about how mitochondria produce energy?'}
For a full list of model providers that support JSON mode, see this table.
Tool calling
For models that support it, tool calling can be very convenient for structured output. It removes the guesswork around how best to prompt schemas in favor of a built-in model feature.
It works by first binding the desired schema either directly or via a LangChain tool to a
chat model using the .bind_tools() method. The model will then generate an AIMessage containing
a tool_calls field containing args that match the desired shape.
There are several acceptable formats you can use to bind tools to a model in LangChain. Here's one example:
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
class ResponseFormatter(BaseModel):
"""Always use this tool to structure your response to the user."""
answer: str = Field(description="The answer to the user's question")
followup_question: str = Field(description="A followup question the user could ask")
model = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
model_with_tools = model.bind_tools([ResponseFormatter])
ai_msg = model_with_tools.invoke("What is the powerhouse of the cell?")
ai_msg.tool_calls[0]["args"]
{'answer': "The powerhouse of the cell is the mitochondrion. It generates most of the cell's supply of adenosine triphosphate (ATP), which is used as a source of chemical energy.",
'followup_question': 'How do mitochondria generate ATP?'}
Tool calling is a generally consistent way to get a model to generate structured output, and is the default technique
used for the .with_structured_output() method when a model supports it.
The following how-to guides are good practical resources for using function/tool calling for structured output:
For a full list of model providers that support tool calling, see this table.
Few-shot prompting
One of the most effective ways to improve model performance is to give a model examples of what you want it to do. The technique of adding example inputs and expected outputs to a model prompt is known as "few-shot prompting". The technique is based on the Language Models are Few-Shot Learners paper. There are a few things to think about when doing few-shot prompting:
- How are examples generated?
- How many examples are in each prompt?
- How are examples selected at runtime?
- How are examples formatted in the prompt?
Here are the considerations for each.
1. Generating examples
The first and most important step of few-shot prompting is coming up with a good dataset of examples. Good examples should be relevant at runtime, clear, informative, and provide information that was not already known to the model.
At a high-level, the basic ways to generate examples are:
- Manual: a person/people generates examples they think are useful.
- Better model: a better (presumably more expensive/slower) model's responses are used as examples for a worse (presumably cheaper/faster) model.
- User feedback: users (or labelers) leave feedback on interactions with the application and examples are generated based on that feedback (for example, all interactions with positive feedback could be turned into examples).
- LLM feedback: same as user feedback but the process is automated by having models evaluate themselves.
Which approach is best depends on your task. For tasks where a small number core principles need to be understood really well, it can be valuable hand-craft a few really good examples. For tasks where the space of correct behaviors is broader and more nuanced, it can be useful to generate many examples in a more automated fashion so that there's a higher likelihood of there being some highly relevant examples for any runtime input.
Single-turn v.s. multi-turn examples
Another dimension to think about when generating examples is what the example is actually showing.
The simplest types of examples just have a user input and an expected model output. These are single-turn examples.
One more complex type if example is where the example is an entire conversation, usually in which a model initially responds incorrectly and a user then tells the model how to correct its answer. This is called a multi-turn example. Multi-turn examples can be useful for more nuanced tasks where its useful to show common errors and spell out exactly why they're wrong and what should be done instead.
2. Number of examples
Once we have a dataset of examples, we need to think about how many examples should be in each prompt. The key tradeoff is that more examples generally improve performance, but larger prompts increase costs and latency. And beyond some threshold having too many examples can start to confuse the model. Finding the right number of examples is highly dependent on the model, the task, the quality of the examples, and your cost and latency constraints. Anecdotally, the better the model is the fewer examples it needs to perform well and the more quickly you hit steeply diminishing returns on adding more examples. But, the best/only way to reliably answer this question is to run some experiments with different numbers of examples.
3. Selecting examples
Assuming we are not adding our entire example dataset into each prompt, we need to have a way of selecting examples from our dataset based on a given input. We can do this:
- Randomly
- By (semantic or keyword-based) similarity of the inputs
- Based on some other constraints, like token size
LangChain has a number of ExampleSelectors which make it easy to use any of these techniques.
Generally, selecting by semantic similarity leads to the best model performance. But how important this is is again model and task specific, and is something worth experimenting with.
4. Formatting examples
Most state-of-the-art models these days are chat models, so we'll focus on formatting examples for those. Our basic options are to insert the examples:
- In the system prompt as a string
- As their own messages
If we insert our examples into the system prompt as a string, we'll need to make sure it's clear to the model where each example begins and which parts are the input versus output. Different models respond better to different syntaxes, like ChatML, XML, TypeScript, etc.
If we insert our examples as messages, where each example is represented as a sequence of Human, AI messages, we might want to also assign names to our messages like "example_user" and "example_assistant" to make it clear that these messages correspond to different actors than the latest input message.
Formatting tool call examples
One area where formatting examples as messages can be tricky is when our example outputs have tool calls. This is because different models have different constraints on what types of message sequences are allowed when any tool calls are generated.
- Some models require that any AIMessage with tool calls be immediately followed by ToolMessages for every tool call,
- Some models additionally require that any ToolMessages be immediately followed by an AIMessage before the next HumanMessage,
- Some models require that tools are passed in to the model if there are any tool calls / ToolMessages in the chat history.
These requirements are model-specific and should be checked for the model you are using. If your model requires ToolMessages after tool calls and/or AIMessages after ToolMessages and your examples only include expected tool calls and not the actual tool outputs, you can try adding dummy ToolMessages / AIMessages to the end of each example with generic contents to satisfy the API constraints. In these cases it's especially worth experimenting with inserting your examples as strings versus messages, as having dummy messages can adversely affect certain models.
You can see a case study of how Anthropic and OpenAI respond to different few-shot prompting techniques on two different tool calling benchmarks here.
Retrieval
LLMs are trained on a large but fixed dataset, limiting their ability to reason over private or recent information.
Fine-tuning an LLM with specific facts is one way to mitigate this, but is often poorly suited for factual recall and can be costly.
Retrieval is the process of providing relevant information to an LLM to improve its response for a given input.
Retrieval augmented generation (RAG) paper is the process of grounding the LLM generation (output) using the retrieved information.
- See our RAG from Scratch code and video series.
- For a high-level guide on retrieval, see this tutorial on RAG.
RAG is only as good as the retrieved documents’ relevance and quality. Fortunately, an emerging set of techniques can be employed to design and improve RAG systems. We've focused on taxonomizing and summarizing many of these techniques (see below figure) and will share some high-level strategic guidance in the following sections. You can and should experiment with using different pieces together. You might also find this LangSmith guide useful for showing how to evaluate different iterations of your app.
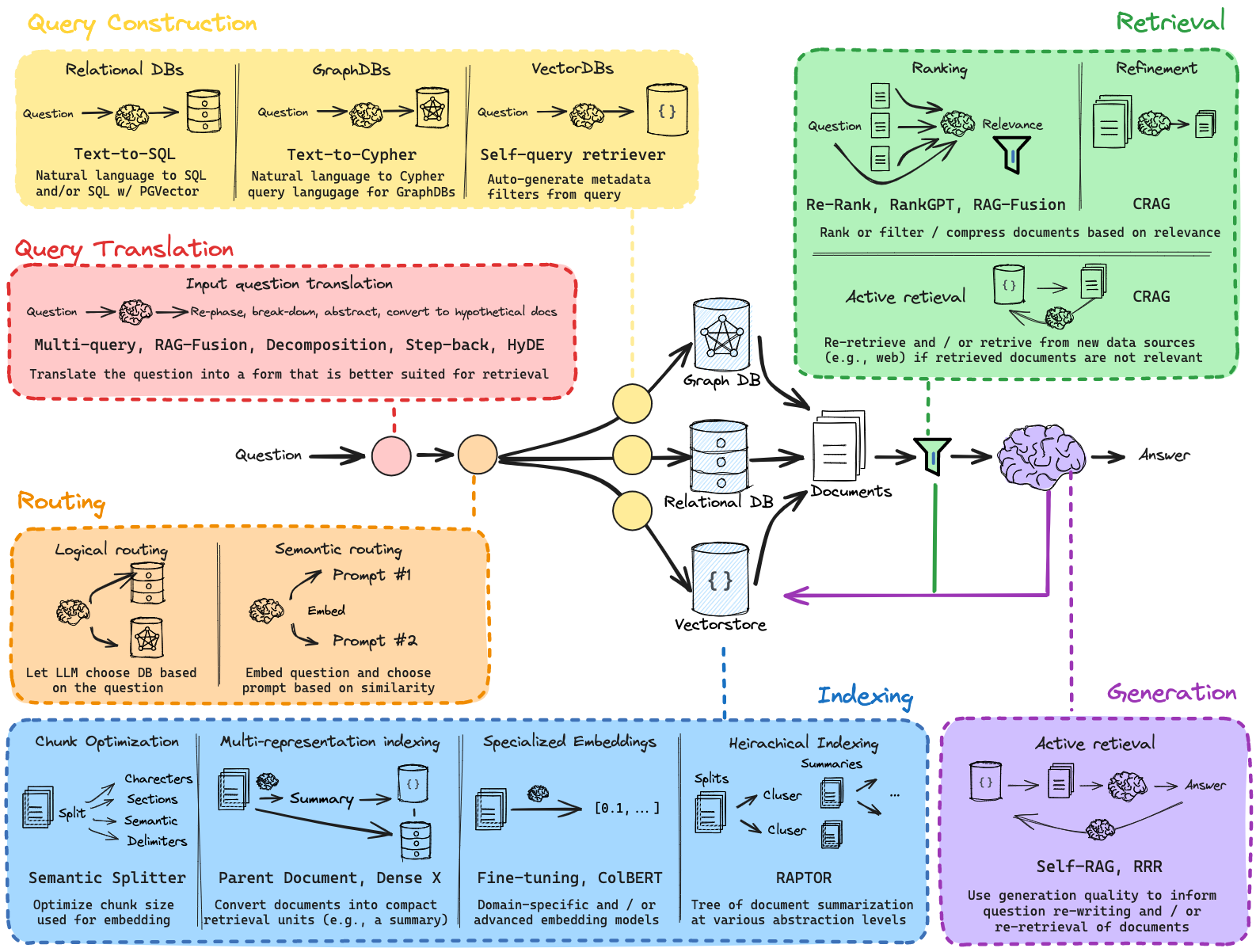
Query Translation
First, consider the user input(s) to your RAG system. Ideally, a RAG system can handle a wide range of inputs, from poorly worded questions to complex multi-part queries. Using an LLM to review and optionally modify the input is the central idea behind query translation. This serves as a general buffer, optimizing raw user inputs for your retrieval system. For example, this can be as simple as extracting keywords or as complex as generating multiple sub-questions for a complex query.
| Name | When to use | Description |
|---|---|---|
| Multi-query | When you need to cover multiple perspectives of a question. | Rewrite the user question from multiple perspectives, retrieve documents for each rewritten question, return the unique documents for all queries. |
| Decomposition | When a question can be broken down into smaller subproblems. | Decompose a question into a set of subproblems / questions, which can either be solved sequentially (use the answer from first + retrieval to answer the second) or in parallel (consolidate each answer into final answer). |
| Step-back | When a higher-level conceptual understanding is required. | First prompt the LLM to ask a generic step-back question about higher-level concepts or principles, and retrieve relevant facts about them. Use this grounding to help answer the user question. Paper. |
| HyDE | If you have challenges retrieving relevant documents using the raw user inputs. | Use an LLM to convert questions into hypothetical documents that answer the question. Use the embedded hypothetical documents to retrieve real documents with the premise that doc-doc similarity search can produce more relevant matches. Paper. |
See our RAG from Scratch videos for a few different specific approaches:
Routing
Second, consider the data sources available to your RAG system. You want to query across more than one database or across structured and unstructured data sources. Using an LLM to review the input and route it to the appropriate data source is a simple and effective approach for querying across sources.
| Name | When to use | Description |
|---|---|---|
| Logical routing | When you can prompt an LLM with rules to decide where to route the input. | Logical routing can use an LLM to reason about the query and choose which datastore is most appropriate. |
| Semantic routing | When semantic similarity is an effective way to determine where to route the input. | Semantic routing embeds both query and, typically a set of prompts. It then chooses the appropriate prompt based upon similarity. |
See our RAG from Scratch video on routing.
Query Construction
Third, consider whether any of your data sources require specific query formats. Many structured databases use SQL. Vector stores often have specific syntax for applying keyword filters to document metadata. Using an LLM to convert a natural language query into a query syntax is a popular and powerful approach. In particular, text-to-SQL, text-to-Cypher, and query analysis for metadata filters are useful ways to interact with structured, graph, and vector databases respectively.
| Name | When to Use | Description |
|---|---|---|
| Text to SQL | If users are asking questions that require information housed in a relational database, accessible via SQL. | This uses an LLM to transform user input into a SQL query. |
| Text-to-Cypher | If users are asking questions that require information housed in a graph database, accessible via Cypher. | This uses an LLM to transform user input into a Cypher query. |
| Self Query | If users are asking questions that are better answered by fetching documents based on metadata rather than similarity with the text. | This uses an LLM to transform user input into two things: (1) a string to look up semantically, (2) a metadata filter to go along with it. This is useful because oftentimes questions are about the METADATA of documents (not the content itself). |
See our blog post overview and RAG from Scratch video on query construction, the process of text-to-DSL where DSL is a domain specific language required to interact with a given database. This converts user questions into structured queries.
Indexing
Fourth, consider the design of your document index. A simple and powerful idea is to decouple the documents that you index for retrieval from the documents that you pass to the LLM for generation. Indexing frequently uses embedding models with vector stores, which compress the semantic information in documents to fixed-size vectors.
Many RAG approaches focus on splitting documents into chunks and retrieving some number based on similarity to an input question for the LLM. But chunk size and chunk number can be difficult to set and affect results if they do not provide full context for the LLM to answer a question. Furthermore, LLMs are increasingly capable of processing millions of tokens.
Two approaches can address this tension: (1) Multi Vector retriever using an LLM to translate documents into any form (e.g., often into a summary) that is well-suited for indexing, but returns full documents to the LLM for generation. (2) ParentDocument retriever embeds document chunks, but also returns full documents. The idea is to get the best of both worlds: use concise representations (summaries or chunks) for retrieval, but use the full documents for answer generation.
| Name | Index Type | Uses an LLM | When to Use | Description |
|---|---|---|---|---|
| Vector store | Vector store | No | If you are just getting started and looking for something quick and easy. | This is the simplest method and the one that is easiest to get started with. It involves creating embeddings for each piece of text. |
| ParentDocument | Vector store + Document Store | No | If your pages have lots of smaller pieces of distinct information that are best indexed by themselves, but best retrieved all together. | This involves indexing multiple chunks for each document. Then you find the chunks that are most similar in embedding space, but you retrieve the whole parent document and return that (rather than individual chunks). |
| Multi Vector | Vector store + Document Store | Sometimes during indexing | If you are able to extract information from documents that you think is more relevant to index than the text itself. | This involves creating multiple vectors for each document. Each vector could be created in a myriad of ways - examples include summaries of the text and hypothetical questions. |
| Time-Weighted Vector store | Vector store | No | If you have timestamps associated with your documents, and you want to retrieve the most recent ones | This fetches documents based on a combination of semantic similarity (as in normal vector retrieval) and recency (looking at timestamps of indexed documents) |
- See our RAG from Scratch video on indexing fundamentals
- See our RAG from Scratch video on multi vector retriever
Fifth, consider ways to improve the quality of your similarity search itself. Embedding models compress text into fixed-length (vector) representations that capture the semantic content of the document. This compression is useful for search / retrieval, but puts a heavy burden on that single vector representation to capture the semantic nuance / detail of the document. In some cases, irrelevant or redundant content can dilute the semantic usefulness of the embedding.
ColBERT is an interesting approach to address this with a higher granularity embeddings: (1) produce a contextually influenced embedding for each token in the document and query, (2) score similarity between each query token and all document tokens, (3) take the max, (4) do this for all query tokens, and (5) take the sum of the max scores (in step 3) for all query tokens to get a query-document similarity score; this token-wise scoring can yield strong results.
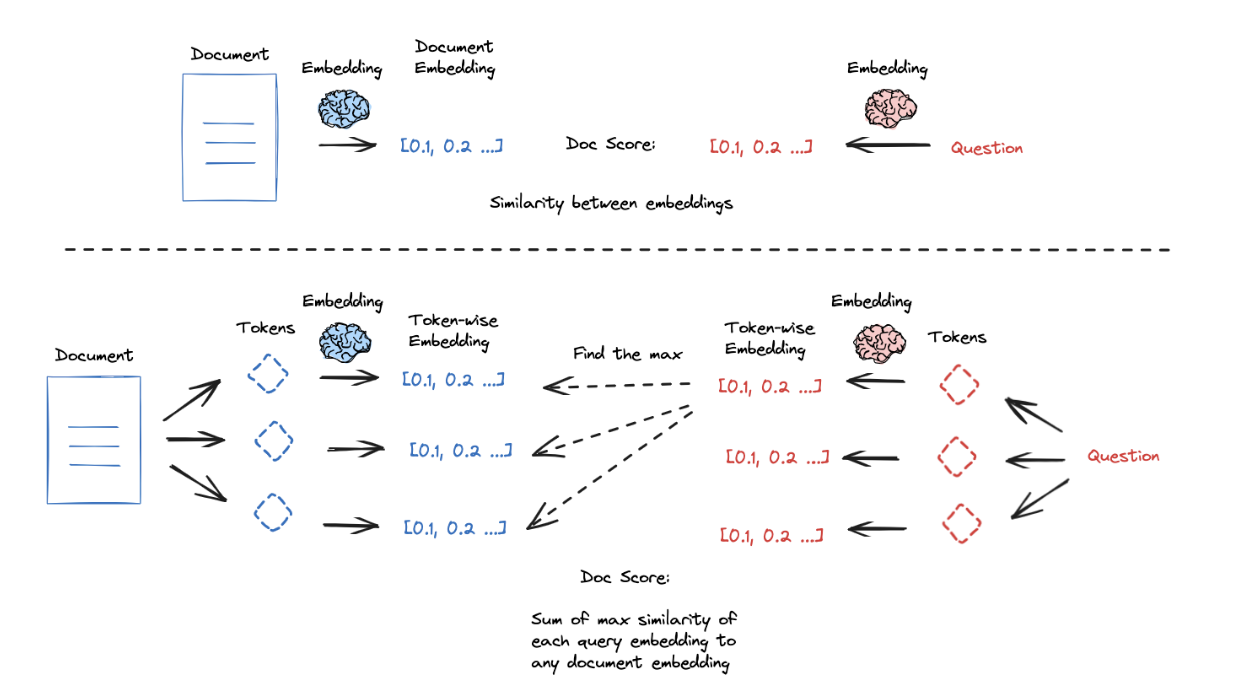
There are some additional tricks to improve the quality of your retrieval. Embeddings excel at capturing semantic information, but may struggle with keyword-based queries. Many vector stores offer built-in hybrid-search to combine keyword and semantic similarity, which marries the benefits of both approaches. Furthermore, many vector stores have maximal marginal relevance, which attempts to diversify the results of a search to avoid returning similar and redundant documents.
| Name | When to use | Description |
|---|---|---|
| ColBERT | When higher granularity embeddings are needed. | ColBERT uses contextually influenced embeddings for each token in the document and query to get a granular query-document similarity score. Paper. |
| Hybrid search | When combining keyword-based and semantic similarity. | Hybrid search combines keyword and semantic similarity, marrying the benefits of both approaches. Paper. |
| Maximal Marginal Relevance (MMR) | When needing to diversify search results. | MMR attempts to diversify the results of a search to avoid returning similar and redundant documents. |
See our RAG from Scratch video on ColBERT.
Post-processing
Sixth, consider ways to filter or rank retrieved documents. This is very useful if you are combining documents returned from multiple sources, since it can can down-rank less relevant documents and / or compress similar documents.
| Name | Index Type | Uses an LLM | When to Use | Description |
|---|---|---|---|---|
| Contextual Compression | Any | Sometimes | If you are finding that your retrieved documents contain too much irrelevant information and are distracting the LLM. | This puts a post-processing step on top of another retriever and extracts only the most relevant information from retrieved documents. This can be done with embeddings or an LLM. |
| Ensemble | Any | No | If you have multiple retrieval methods and want to try combining them. | This fetches documents from multiple retrievers and then combines them. |
| Re-ranking | Any | Yes | If you want to rank retrieved documents based upon relevance, especially if you want to combine results from multiple retrieval methods . | Given a query and a list of documents, Rerank indexes the documents from most to least semantically relevant to the query. |
See our RAG from Scratch video on RAG-Fusion (paper), on approach for post-processing across multiple queries: Rewrite the user question from multiple perspectives, retrieve documents for each rewritten question, and combine the ranks of multiple search result lists to produce a single, unified ranking with Reciprocal Rank Fusion (RRF).
Generation
Finally, consider ways to build self-correction into your RAG system. RAG systems can suffer from low quality retrieval (e.g., if a user question is out of the domain for the index) and / or hallucinations in generation. A naive retrieve-generate pipeline has no ability to detect or self-correct from these kinds of errors. The concept of "flow engineering" has been introduced in the context of code generation: iteratively build an answer to a code question with unit tests to check and self-correct errors. Several works have applied this RAG, such as Self-RAG and Corrective-RAG. In both cases, checks for document relevance, hallucinations, and / or answer quality are performed in the RAG answer generation flow.
We've found that graphs are a great way to reliably express logical flows and have implemented ideas from several of these papers using LangGraph, as shown in the figure below (red - routing, blue - fallback, green - self-correction):
- Routing: Adaptive RAG (paper). Route questions to different retrieval approaches, as discussed above
- Fallback: Corrective RAG (paper). Fallback to web search if docs are not relevant to query
- Self-correction: Self-RAG (paper). Fix answers w/ hallucinations or don’t address question
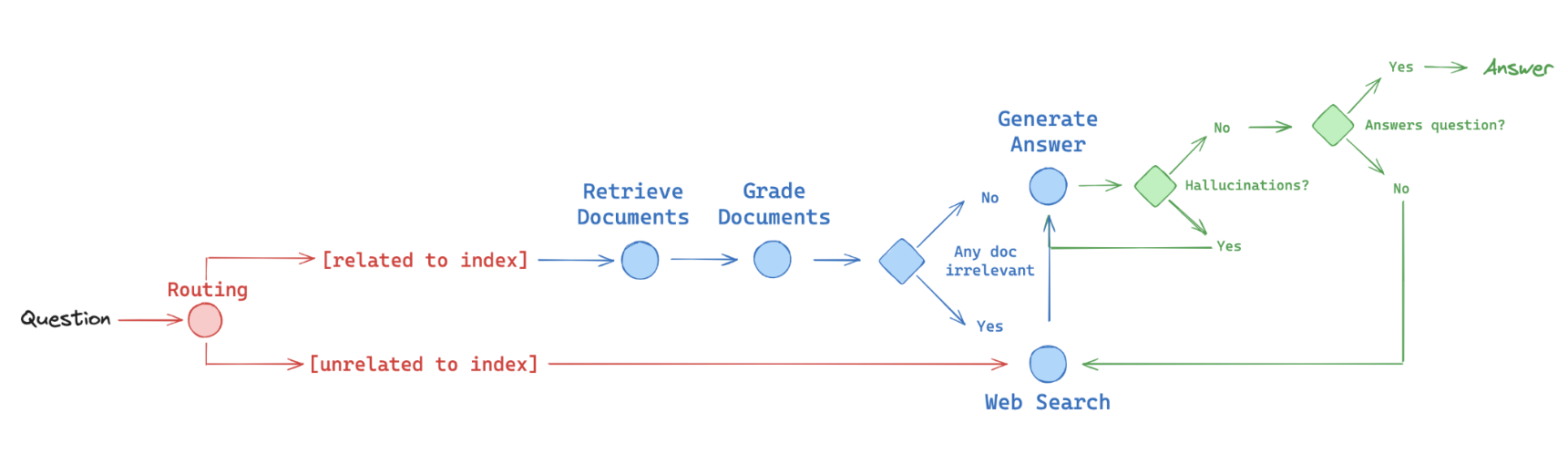
| Name | When to use | Description |
|---|---|---|
| Self-RAG | When needing to fix answers with hallucinations or irrelevant content. | Self-RAG performs checks for document relevance, hallucinations, and answer quality during the RAG answer generation flow, iteratively building an answer and self-correcting errors. |
| Corrective-RAG | When needing a fallback mechanism for low relevance docs. | Corrective-RAG includes a fallback (e.g., to web search) if the retrieved documents are not relevant to the query, ensuring higher quality and more relevant retrieval. |
See several videos and cookbooks showcasing RAG with LangGraph:
- LangGraph Corrective RAG
- LangGraph combining Adaptive, Self-RAG, and Corrective RAG
- Cookbooks for RAG using LangGraph
See our LangGraph RAG recipes with partners:
Text splitting
LangChain offers many different types of text splitters.
These all live in the langchain-text-splitters package.
Table columns:
- Name: Name of the text splitter
- Classes: Classes that implement this text splitter
- Splits On: How this text splitter splits text
- Adds Metadata: Whether or not this text splitter adds metadata about where each chunk came from.
- Description: Description of the splitter, including recommendation on when to use it.
| Name | Classes | Splits On | Adds Metadata | Description |
|---|---|---|---|---|
| Recursive | RecursiveCharacterTextSplitter, RecursiveJsonSplitter | A list of user defined characters | Recursively splits text. This splitting is trying to keep related pieces of text next to each other. This is the recommended way to start splitting text. | |
| HTML | HTMLHeaderTextSplitter, HTMLSectionSplitter | HTML specific characters | ✅ | Splits text based on HTML-specific characters. Notably, this adds in relevant information about where that chunk came from (based on the HTML) |
| Markdown | MarkdownHeaderTextSplitter, | Markdown specific characters | ✅ | Splits text based on Markdown-specific characters. Notably, this adds in relevant information about where that chunk came from (based on the Markdown) |
| Code | many languages | Code (Python, JS) specific characters | Splits text based on characters specific to coding languages. 15 different languages are available to choose from. | |
| Token | many classes | Tokens | Splits text on tokens. There exist a few different ways to measure tokens. | |
| Character | CharacterTextSplitter | A user defined character | Splits text based on a user defined character. One of the simpler methods. | |
| Semantic Chunker (Experimental) | SemanticChunker | Sentences | First splits on sentences. Then combines ones next to each other if they are semantically similar enough. Taken from Greg Kamradt | |
| Integration: AI21 Semantic | AI21SemanticTextSplitter | ✅ | Identifies distinct topics that form coherent pieces of text and splits along those. |
Evaluation
Evaluation is the process of assessing the performance and effectiveness of your LLM-powered applications. It involves testing the model's responses against a set of predefined criteria or benchmarks to ensure it meets the desired quality standards and fulfills the intended purpose. This process is vital for building reliable applications.
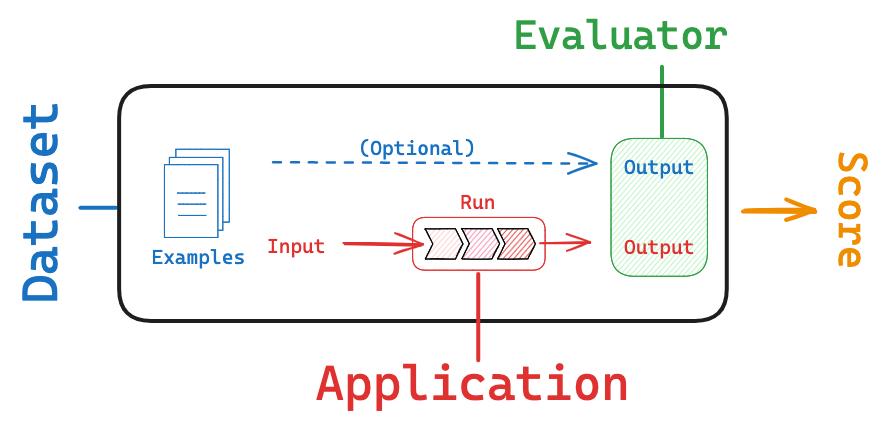
LangSmith helps with this process in a few ways:
- It makes it easier to create and curate datasets via its tracing and annotation features
- It provides an evaluation framework that helps you define metrics and run your app against your dataset
- It allows you to track results over time and automatically run your evaluators on a schedule or as part of CI/Code
To learn more, check out this LangSmith guide.
Tracing
A trace is essentially a series of steps that your application takes to go from input to output.
Traces contain individual steps called runs. These can be individual calls from a model, retriever,
tool, or sub-chains.
Tracing gives you observability inside your chains and agents, and is vital in diagnosing issues.
For a deeper dive, check out this LangSmith conceptual guide.